ProjectsMLOps / Machine Learning
End-to-End Machine Learning Pipeline
A production-style MLOps pipeline that covers dataset experimentation, automated preprocessing, MLflow model training, CI retraining, Docker packaging, and observability with Prometheus and Grafana.
My Role
- 01Designed the full machine learning lifecycle from experimentation, automated preprocessing, model training, CI retraining, deployment preparation, and monitoring.
- 02Built a production-style MLOps structure across experiment, modelling, MLflow project, and monitoring deliverables.
- 03Prepared operational evidence and supporting files for MLflow, DagsHub, GitHub Actions, Docker, Prometheus, and Grafana workflows.
Features
- 01Completed the experimentation stage using the MSML experiment template, including dataset loading, exploratory data analysis, and manual preprocessing before automation.
- 02Converted the notebook preprocessing flow into an automated Python preprocessing script that returns training-ready data and can be triggered through GitHub Actions.
- 03Built the modelling stage with MLflow Tracking, hyperparameter tuning, manual metric logging, and additional artifacts stored through an online DagsHub tracking setup.
- 04Created an MLflow Project based CI workflow that retrains the model automatically when the GitHub Actions trigger runs.
- 05Extended the CI workflow to preserve model artifacts and build Docker images for Docker Hub using the MLflow Docker build flow.
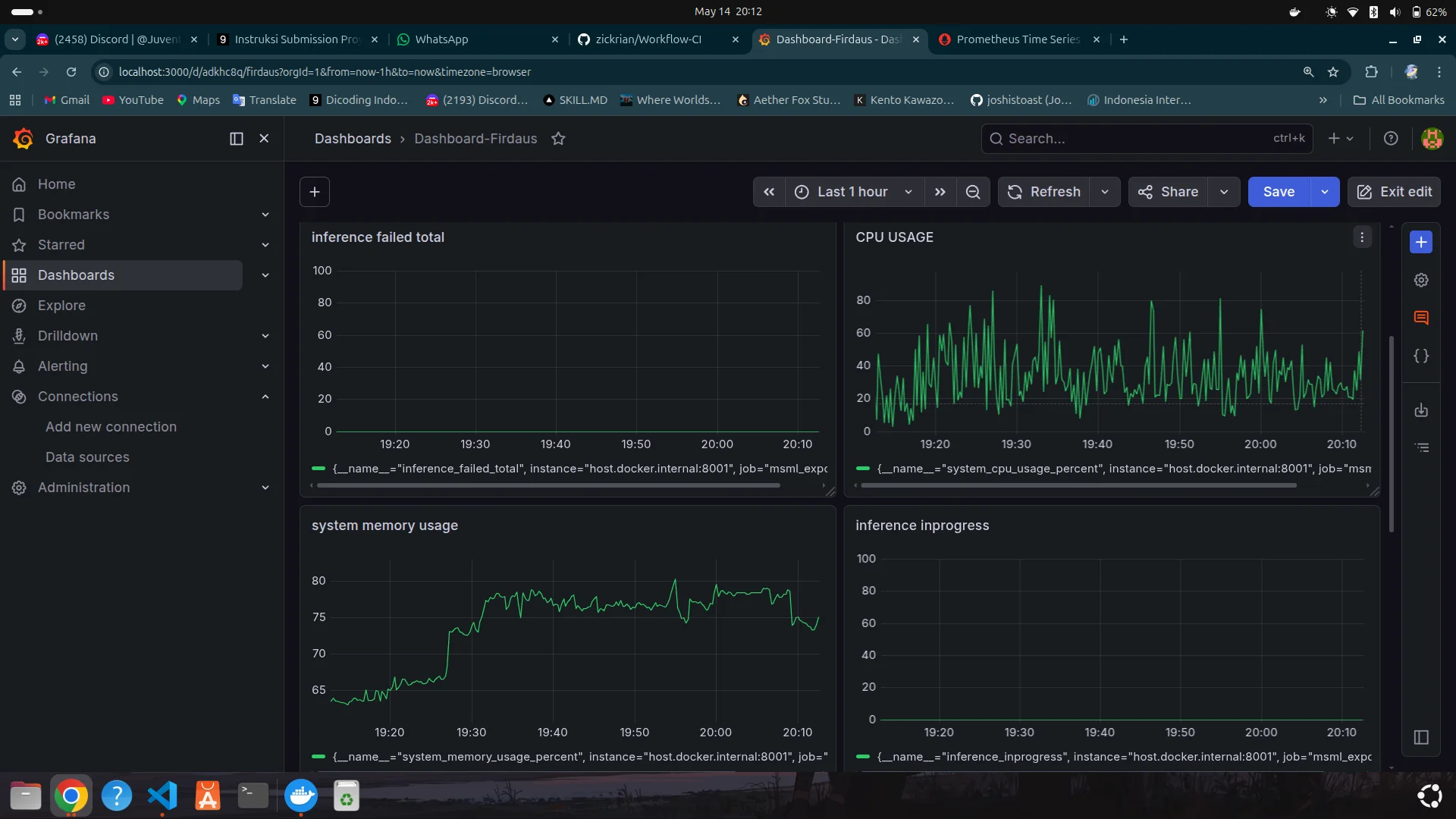
- 06Prepared local model serving and connected observability through Prometheus exporter metrics, Prometheus configuration, and Grafana dashboards.
- 07Implemented advanced Grafana monitoring coverage with multiple system/model metrics and alerting rules for production-style model observation.
Impact
- Demonstrates an end-to-end MLOps workflow rather than only a standalone notebook or model training script.
- Makes preprocessing and retraining repeatable through automation, reducing manual steps and improving project reproducibility.
- Connects model development with CI, artifact management, containerization, monitoring, and alerting so the system is closer to real deployment practice.
- Shows how model development can be operationalized with repeatable pipelines, tracked experiments, deployable artifacts, and observability.
Stack
Pythonscikit-learnMLflowDagsHubGitHub ActionsDockerPrometheusGrafana
Notes
Private production-style MLOps project covering automated preprocessing, MLflow + DagsHub tracking with tuning and artifacts, CI retraining with Docker image build, and Prometheus/Grafana monitoring with alerting.